Distance Timings¶
Our publication uses numba based distances from the aeon packages in our clustering implementations and experiments. In this notebook we compare the performance of the aeon distances to the dtw package, tslearn and sktime implementations of DTW.
We use the follow versions for each package in the default output:
aeon-0.3.0
dtw-1.4.0
tslearn-0.5.3.2
sktime-0.20.0
[27]:
import time
import warnings
import matplotlib.pyplot as plt
import pandas as pd
from aeon.distances import dtw_distance as aeon_dtw
from aeon.testing.data_generation import make_example_2d_numpy_series
from dtw import dtw as dtw_python_dtw
from sktime.dists_kernels import DtwDist as sktime_dtw
from tslearn.metrics import dtw as tslearn_dtw
warnings.filterwarnings("ignore") # Hide warnings
[ ]:
def timing_experiment(x, y, distance_callable, average=10, params=None):
"""Time a distance experiment."""
if params is None:
params = {}
total_time = 0
for i in range(0, average):
start = time.time()
distance_callable(x, y, **params)
total_time += time.time() - start
return total_time / average
# dummy run to compile numba etc
x = make_example_2d_numpy_series(10, 10, random_state=0)
tslearn_x = x.swapaxes(0, 1)
timing_experiment(x, x, aeon_dtw, average=1)
timing_experiment(x, x, dtw_python_dtw, average=1)
timing_experiment(tslearn_x, tslearn_x, tslearn_dtw, average=1)
timing_experiment(x, x, sktime_dtw(), average=1)
x
Univariate Distance Timings¶
In this experiment we compare performance on a univariate series, raising the series length by 50 each step and averaging over 10 runs.
[33]:
aeon_timing = []
dtw_python_timing = []
tslearn_timing = []
sktime_timing = []
lengths = []
for i in range(50, 550, 50):
lengths.append(i)
x = make_example_2d_numpy_series(1, i, random_state=0)
y = make_example_2d_numpy_series(1, i, random_state=1)
tslearn_x = x.swapaxes(0, 1)
tslearn_y = y.swapaxes(0, 1)
aeon_timing.append(timing_experiment(x, y, aeon_dtw))
dtw_python_timing.append(timing_experiment(x, y, dtw_python_dtw))
tslearn_timing.append(timing_experiment(tslearn_x, tslearn_y, tslearn_dtw))
sktime_timing.append(timing_experiment(x, y, sktime_dtw()))
[34]:
print(aeon_timing)
print(tslearn_timing)
print(dtw_python_timing)
print(sktime_timing)
[1.3828277587890625e-06, 4.76837158203125e-07, 6.198883056640625e-07, 5.006790161132813e-07, 8.106231689453125e-07, 5.960464477539062e-07, 7.867813110351562e-07, 7.867813110351562e-07, 9.059906005859375e-07, 7.867813110351562e-07]
[5.0902366638183594e-05, 2.7585029602050782e-05, 3.2281875610351564e-05, 3.4308433532714845e-05, 2.8324127197265624e-05, 3.550052642822266e-05, 3.1995773315429685e-05, 2.9015541076660157e-05, 3.108978271484375e-05, 3.230571746826172e-05]
[0.0004210948944091797, 0.0003742218017578125, 0.0007395029067993164, 0.0010912895202636718, 0.001444101333618164, 0.0019306898117065429, 0.0025099515914916992, 0.0030148983001708984, 0.0037273406982421876, 0.004485988616943359]
[0.023533725738525392, 0.006352543830871582, 0.008351731300354003, 0.008076000213623046, 0.008314299583435058, 0.009503388404846191, 0.00986309051513672, 0.04659316539764404, 0.0422865629196167, 0.042216014862060544]
[35]:
plt.plot(aeon_timing, label="aeon")
plt.plot(tslearn_timing, label="tslearn")
plt.plot(dtw_python_timing, label="dtw")
plt.plot(sktime_timing, label="sktime")
plt.legend()
plt.xticks(list(range(len(lengths))), lengths)
plt.show()

Multivariate Distance Timings¶
In this experiment we compare performance on a multivariate series, raising both the series length and number of channels by 50 each step and averaging over 10 runs.
The dtw package does not support multivariate series, so we exclude it.
[37]:
aeon_timing = []
tslearn_timing = []
sktime_timing = []
lengths = []
for i in range(50, 550, 50):
lengths.append(i)
x = make_example_2d_numpy_series(i, i, random_state=0)
y = make_example_2d_numpy_series(i, i, random_state=1)
tslearn_x = x.swapaxes(0, 1)
tslearn_y = y.swapaxes(0, 1)
aeon_timing.append(timing_experiment(x, y, aeon_dtw))
tslearn_timing.append(timing_experiment(tslearn_x, tslearn_y, tslearn_dtw))
sktime_timing.append(timing_experiment(x, y, sktime_dtw()))
[38]:
print(aeon_timing)
print(tslearn_timing)
print(sktime_timing)
[4.062652587890625e-05, 0.00024292469024658203, 0.0008319139480590821, 0.0024091720581054686, 0.005573940277099609, 0.008205103874206542, 0.012984180450439453, 0.02905399799346924, 0.031551194190979, 0.0444720983505249]
[0.00014519691467285156, 0.00034160614013671874, 0.0011731863021850586, 0.0029234886169433594, 0.006116819381713867, 0.010189390182495118, 0.01739170551300049, 0.0314178466796875, 0.04181606769561767, 0.05908267498016358]
[0.007526421546936035, 0.006715965270996094, 0.007675814628601074, 0.011852359771728516, 0.014245891571044922, 0.02002761363983154, 0.028622007369995116, 0.06879444122314453, 0.08343648910522461, 0.10684428215026856]
[39]:
plt.plot(aeon_timing, label="aeon")
plt.plot(tslearn_timing, label="tslearn")
plt.plot(sktime_timing, label="sktime")
plt.legend()
plt.xticks(list(range(len(lengths))), lengths)
plt.show()

Larger multivariate experiment¶
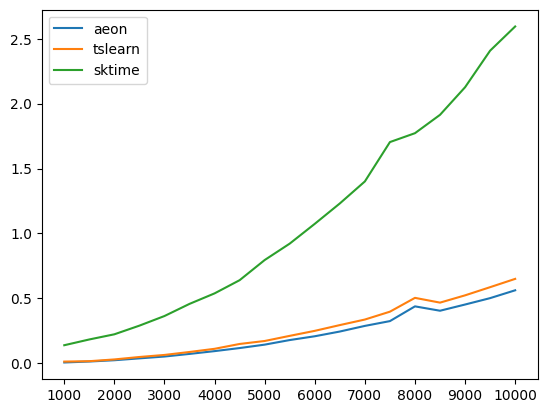
We keep the series compared above small to keep the notebook runtime low. In the following pre-computed experiment we compare the performance for larger series length and dimensionality averaged over 30 runs per step.
[40]:
# start 1000, end 10000, step 500, 30 average runs
csv = pd.read_csv("results/distance_notebook_timings.csv", index_col=0)
print(csv)
1000 1500 2000 2500 3000 3500 4000 \
aeon 0.005453 0.012845 0.022739 0.037193 0.051308 0.071451 0.092952
tslearn 0.012304 0.015375 0.028867 0.047718 0.063504 0.086363 0.110766
sktime 0.138374 0.182864 0.222571 0.289339 0.363408 0.457018 0.537899
4500 5000 5500 6000 6500 7000 7500 \
aeon 0.116585 0.142927 0.178241 0.207480 0.243924 0.287327 0.324288
tslearn 0.148099 0.170989 0.210569 0.249226 0.293594 0.336350 0.396900
sktime 0.639533 0.794833 0.921391 1.073838 1.230945 1.400597 1.703857
8000 8500 9000 9500 10000
aeon 0.437878 0.404185 0.452040 0.501346 0.561733
tslearn 0.503390 0.466680 0.522787 0.585782 0.649676
sktime 1.772326 1.913860 2.126502 2.408306 2.594621
[41]:
plt.plot(csv.iloc[0], label="aeon")
plt.plot(csv.iloc[1], label="tslearn")
plt.plot(csv.iloc[2], label="sktime")
plt.legend()
lengths = list(csv.columns.values)
plt.xticks(list(range(0, len(lengths), 2)), lengths[::2])
plt.show()
Generated using nbsphinx. The Jupyter notebook can be found here.
![]()